
The world of search engine optimisation is both intricate and layered, but for us, it’s a fascinating digital landscape we navigate daily with enthusiasm. Among the many elements we work with, one small yet crucial component is the often-overlooked robots.txt file.
While it may appear simple, configuring robots.txt correctly requires a fine balance of creativity, strategy, and technical precision — all the ingredients of a successful, high-performing SEO campaign.
To help our clients better understand why this file matters and how it contributes to the overall efficiency of their digital presence, we’ve created a straightforward guide. Inside, you’ll discover everything you need to know about the robots.txt file, what it does, and the important role it plays in shaping your digital footprint.
Take a moment to explore how robots.txt works — and how this tiny file can hold powerful influence over your online domain.
What is The Robots.txt File?
Understanding the robots.txt file begins with a look at how Google operates as a search engine — specifically, how it decides where your website should appear in search rankings.
Imagine an invisible army of digital agents scouring the web, exploring every page they encounter. In Google’s case, these agents are known as user agents, most commonly referred to as Googlebots or crawlers. These programmed bots act like tiny web spiders, systematically examining websites to determine how they should be indexed in search results.
Think of them as scouts collecting data for search engines, helping to decide where your content should rank. These bots review everything — from product pages and images to contact forms and backend folders — to build a comprehensive picture of your site.
However, not every part of your website should be publicly visible or indexed. Often, backend files or folders may contain technical or sensitive information — or simply irrelevant content — that you don’t want appearing in search results. That’s where the robots.txt file comes in.
By using the user-agent and disallow directives within your robots.txt file, you can control which parts of your site these bots are allowed to access. Essentially, you’re telling search engines: “Don’t crawl this section — it’s not for public viewing.”
Many popular SEO plugins for platforms like WordPress offer user-friendly interfaces to manage your robots.txt file, making this technical process far more accessible — even for non-developers.
In simple terms, robots.txt allows you to restrict access to specific parts of your website that you don’t want indexed. Unless you clearly set these rules using disallow commands, search engines will attempt to crawl everything they find.
So, think of the robots.txt file as a gatekeeper — a way of saying to Google, “This page isn’t meant to be seen or ranked. Please skip it.”

When you have a user-agent disallow, the crawler will recognise the robots.txt file and understand that certain pages shouldn’t be included in search engine indexing.
Every website should have a robots.txt file to instruct user-agents (like Googlebot) on how to behave — specifically whether they should follow the robots exclusion guidelines.
This file is simple in structure and can be created by you (or more likely, your technical expert or webmaster) using something as basic as Notepad, a text editor, or any standard word processor. With just a few lines of code, you can effectively restrict crawler access to parts of your site. Using a robots.txt file gives you the ability to issue a user-agent-specific disallow directive to tools like Googlebot.
Most websites already include a robots.txt file. You can easily check if yours does by visiting the base URL of your site and adding /robots.txt at the end — for example:
https://digitotal.com.au//robots.txt
If your site has been set up properly, this file will contain strategically placed lines of code that guide the behaviour of user agents.
Inside the file, you’ll likely see lines that begin with “Disallow.” These are the commands that tell Googlebot and other crawlers which pages or directories they should avoid. A robots.txt file can be very short or quite extensive — depending on how much of your site you want to control from a crawl and indexing standpoint.
Ultimately, robots.txt helps impose crawl delays and prevents unwanted pages from being indexed — putting you in control of what gets seen and what stays hidden.
What Do Robots.txt Files Do on Search Engines?
At its most basic level, the robots.txt file gives you control over which user agents (like Googlebot) can crawl your site, and which parts of your website they’re allowed to access or index. In essence, it tells search engines, “Don’t crawl this content.”
Sometimes, even if you haven’t intended for a page to be indexed, search engines may still crawl it — especially if there are multiple links pointing to that URL. When that happens, user agents may interpret those links as signals of authority, leading the page to be indexed and appear in search results, often with a generated meta description.
However, if a meta description can’t be found or appears incorrectly in search results, it may point to an issue in your robots.txt file. In these cases, it’s time to review and update your file — ensuring that user-agent directives are working in your favour to improve visibility, fix crawl errors, or guide bots more effectively.
The robots.txt file allows you to block a single URL, an entire directory, or specific sections of your website from being accessed by search engines. It gives you granular control over what should remain private or excluded from search engine results.
The larger and more complex your website, the more lines your robots.txt file is likely to have — and the more advanced your user-agent instructions will become.
That said, the more directives you include, the more work user agents need to do when crawling your site. This can sometimes result in crawl delays or even impact your website’s performance, leading to slower load times and lower rankings. That’s why it’s important to use the robots.txt file strategically and sparingly.
If you’re unsure about which pages should be included or excluded in your robots.txt setup, it’s always best to consult a professional (like our tech team here at DigiTotal) to avoid negatively affecting your SEO or site performance.

One way to prevent sluggish website performance is by introducing a purposeful crawl delay in your robots.txt file.
A crawl delay can be added to reduce the load on your server by instructing search engine bots to wait a specified number of seconds between each request. This is done through simple commands written directly into the robots.txt file.
For example, if your robots.txt includes several user-agent disallow lines across multiple pages, you might benefit from telling the crawler to pause — say, 30 seconds — before moving on to the next instruction or page. This can help keep your site running smoothly while still ensuring important pages remain accessible to search engines.
Depending on your site’s size and structure, using a crawl delay can be an effective strategy to optimise performance and maintain strong search visibility. However, today’s search engine crawlers and servers are highly advanced. In many cases, your server may already adapt dynamically to changes in activity, reducing the need to manually implement crawl delays.
As web technology evolves, we’re seeing a major shift toward reactive, intelligent systems that adapt in real-time — something we believe represents the future of web development and design. Still, regardless of how advanced these systems become, your robots.txt file remains a foundational part of your site’s technical setup. That’s why it’s essential to understand its role from the start.
Important Note:
Having a robots.txt file in place doesn’t guarantee that all bots or crawlers will respect its rules. There are tools and software designed to bypass or ignore robots.txt directives entirely, crawling content even when it’s been disallowed.
As with anything in digital strategy, it’s important to be intentional with what you choose to include or restrict within your robots.txt file. Being strategic from the outset can help you avoid unexpected issues and protect your site’s integrity.
What Should Your Robots.txt Look Like?
A robots.txt file is essentially a way for you to communicate directly with search engines and software agents — not with human users or customers. Google recommends that all websites include a robots.txt file, and it does factor this into its overall ranking considerations.
The file itself isn’t complex — just plain lines of text on a blank page. But these lines serve a specific purpose: they tell Googlebots (Google’s search engine crawlers) and other web crawlers what they are allowed to access on your site, and what they’re not.
Depending on how your robots.txt file is written, these “digital bots” will either follow the path to index a page, or encounter a disallow directive that blocks them from crawling specific content or directories.
To get started, you simply create a basic text file where these rules are outlined. It’s important to name the file exactly as “robots.txt” — variations like robots txt, robot txt, or robot.txt won’t be recognised by user agents and will be ignored.
The term user-agent refers to the specific crawler (e.g., Googlebot, Bingbot, etc.) you want to target. In your robots.txt file, you’ll need to specify which user agent you’re giving instructions to. If you want to restrict access for all crawlers across the board, you can use an asterisk (*) as a wildcard to apply the rules universally — for example, to disallow all user agents from crawling specific sections of your site.
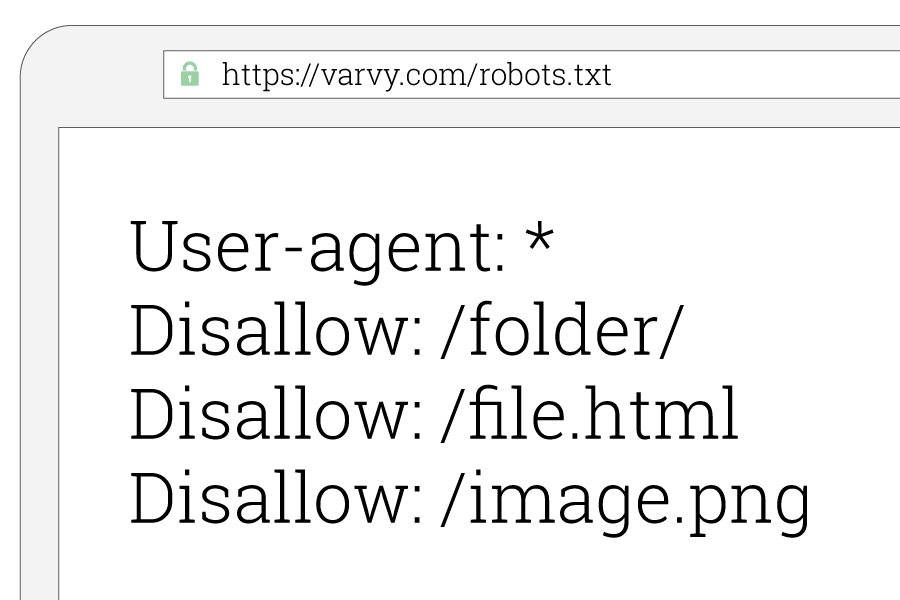
The second line of your robots.txt file is where you list the specific pages or directories you don’t want search engines to access.
This is also a great place to define the location of your sitemap. Including your sitemap in the robots.txt file isn’t just a technical best practice — it’s a smart move to help guide crawlers more efficiently through your website.
Not only does referencing your sitemap grab the crawler’s attention, but it can also contribute positively to your SEO rankings. Most importantly, it ensures that both search engines and your audience can quickly find the most relevant and valuable content on your site — often with just a single click.
What Does This File Look Like?
A typical robots.txt file begins with a line that includes the term “User-agent” or an asterisk (*) to refer to all crawlers, as mentioned earlier. This line grabs the attention of the bots (or “digital robots”) that scan your site. The lines that follow instruct them on what they can and, more importantly, can’t do.
From the second line onward, the file usually includes “Disallow” rules. It’s not strictly necessary to include “Allow” functions in your robots.txt — crawlers will, by default, access any area of your website that hasn’t been specifically restricted.
Be cautious when using both “Allow” and “Disallow” rules. Robots.txt is case-sensitive, so even a slight difference in capitalisation can cause errors or unintended access. You can use the Disallow directive to block access to individual files, folders, file extensions, or even your entire site, if privacy is your goal.
Once you’ve defined all your instructions, it’s time to upload your robots.txt file. This must be placed in your site’s root directory — essentially the main folder that hosts all your backend operations. As long as you have access to the root directory, you can create the file in any text editor and upload it directly to your website.
REMINDER: Always spell the file name exactly as robots.txt in lowercase — any variation will not be recognised by crawlers.
Also, be aware: your robots.txt file isn’t only visible to search engines and web crawlers. It’s publicly accessible to anyone. That means you should never include sensitive information or links to private folders inside this file. If, for instance, you have a password file or private customer data in a folder, referencing it in robots.txt can actually expose it to hackers looking for vulnerabilities. Many cyber attacks start with a quick scan of the robots.txt file — so be very strategic about what you place in there.
Pro Tip: Regularly review your robots.txt file to ensure you’re not accidentally blocking pages or directories you want indexed. Google won’t amplify pages it can’t see. In our view, robots.txt is a technical art form — it might be a small file, but it has massive implications for SEO when done right. Not sure how to check it? That’s where our team at Digitotal can help.
What Does Robots.txt Mean for Your SEO?
This small but powerful file plays a major role in how Google interacts with your website. When used correctly — and aligned with all the guidelines mentioned above — it can help your site run efficiently and rank competitively. But a single incorrect directive can work against you, potentially harming your search visibility.
One of Google’s key tools for evaluating your site is Google Search Console. This platform can identify errors that might be impacting your rankings — from broken links to crawl issues. Among the most common problems? Robots.txt errors.
A robots.txt issue typically means that bots are being blocked from accessing a particular file, section, or group of pages. As a result, that content won’t appear in search results. If it’s something you want indexed, that can become a major SEO hurdle.
For example, if you run an e-commerce site with hundreds (or thousands) of dynamic pages being generated regularly, keeping a close eye on your robots.txt file is essential. If a new product page is created under a directory that’s been disallowed in robots.txt, it won’t get crawled — and it won’t get traffic. That one line of code could be the reason you’re losing out on visibility and sales.
So, every time you update your site — especially if new pages or sections are added — double-check your robots.txt. One misstep could be costly.
A Final Note on Web Robots and SEO
When done right, a robots.txt file poses no threat at all — it can actually enhance your SEO by creating a smooth, controlled, and efficient path for search engines to follow.
At Digitotal, we’ve handled all types of robots.txt configurations — from the simple to the highly technical — and know how to make this little file work in your favour.
Feeling overwhelmed? That’s completely normal. SEO is full of technicalities and jargon. But that’s exactly what we love about it — and more importantly, it’s what we specialise in. Whether you want us to check your current setup or optimise your robots.txt strategy, we’re here to ensure your site is being crawled and indexed exactly how it should be.